Transaction kernel
The transaction kernel program, written in MASM, is responsible for executing a Miden rollup transaction within the Miden VM. It is defined as MASM kernel.
The kernel provides context-sensitive security which prevents unwanted read and write access. It defines a set of procedures which can be invoked from other contexts; e.g. notes executed in the root context.
In general, the kernel’s procedures must reflect everything users might want to do while executing transactions; from transferring assets to complex smart contract interactions with custom code.
Info
- Learn more about Miden transaction procedures and contexts.
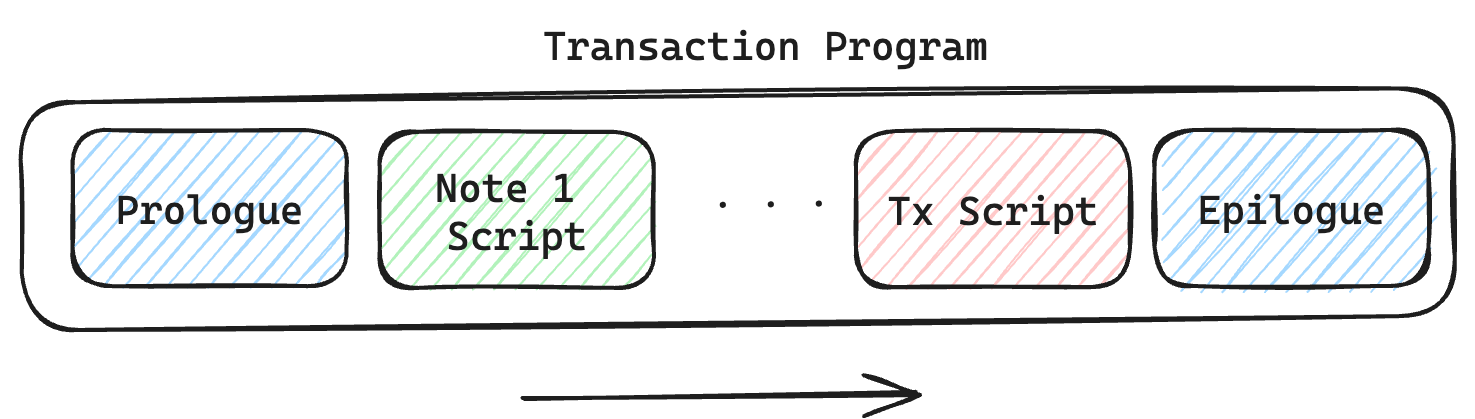
The kernel has a well-defined structure which does the following:
- The prologue prepares the transaction for processing by parsing the transaction data and setting up the root context.
- Note processing executes the note processing loop which consumes each
InputNoteand invokes the note script of each note. - Transaction script processing executes the optional transaction script.
- The epilogue finalizes the transaction by computing the created notes commitment, the final account hash, asserting asset invariant conditions, and asserting the nonce rules are upheld.
Input¶
The transaction kernel program receives two types of inputs, public inputs via the operand_stack and private inputs via the advice_provider.
The operand stack holds the global inputs which serve as a commitment to the data being provided via the advice provider.
The advice provider holds data of the last known block, account and input note data. The details are layed out in the next paragraph.
Prologue¶
The transaction prologue executes at the beginning of a transaction.
It performs the following tasks:
- Unhashes the inputs and lays them out in the root context memory.
- Builds a single vault (tx vault) containing assets of all inputs (input notes and initial account state).
- Verifies that all input notes are present in the note DB.
In other words, the prologue stores all provided information from the inputs and the advice provider into the appropriate memory slots. It then reads the data for the account and notes from the advice provider, writes it to memory, hashes it, and verifies that the resulting hash matches the commitments provided via the stack. Finally, it creates a single vault for the assets that are involved.
The diagram below shows the memory layout. The kernel context has access to all memory slots.

Bookkeeping section¶
The bookkeeping section keeps track of variables which are used internally by the transaction kernel.
Global inputs¶
These are stored in the pre-defined memory slots.
Global inputs come from the operand_stack and go to the VM at transaction execution. They include the block hash, the account ID, the initial account hash, and the nullifier commitment. This is a sequential hash of all (nullifier, ZERO) pairs for the notes consumed in the transaction.
Block data¶
The block data processing involves reading the block data from the advice provider and storing it at the appropriate memory addresses. Block data comes from the latest known block and consists of note, state and tx hash, the block’s previous hash and proof hash, as well as the block number. As the data is read from the advice provider, the block hash is computed. It is asserted that the computed block hash matches the block hash stored in the global inputs.
Chain data¶
Chain data is processed in a similar way to block data. In this case the chain root is recomputed and compared against the chain root stored in the block data section.
Account data¶
Account data processing involves reading the data from the advice provider and storing it at the appropriate memory addresses. The account data consists of account vault roots, storage, and code.
As the account data is read from the advice provider, the account hash is computed. If the account is new then the global initial account hash is updated and the new account is validated. If the account already exists then the computed account hash is asserted against the account hash provided via global inputs. It is also asserted that the account id matches the account id provided via the global inputs (operand_stack).
Input note data¶
Input note processing involves the kernel reading the data from each note and storing it at the appropriate memory addresses. All the data (note, account, and blockchain data) comes from the advice provider and global inputs.
Next to the total number of consumed notes, input note data consists of a serial number, the roots of the script, the inputs and asset vault, its metadata, and all its assets.
As each note is consumed, its hash and nullifier are computed.
The transaction nullifier commitment is computed via a sequential hash of (nullifier, ZERO) pairs for all consumed notes. This step involves authentication such that the input note data provided via the advice provider is consistent with the chain history.
Info
- Note data is required for computing the nullifier, e.g. the note script and the serial number.
- The system needs to know the note data to execute the prologue of a transaction. This is how the note recipient defines the set of users who can consume a specific note.
- The executing account provides the pre-image data to the recipient at the time of execution.
If a transaction script is provided, its root is stored at a pre-defined memory address.
Note processing¶
Input notes are consumed in a loop.
For every note, the MAST root of the note script is loaded onto the stack. Then, by calling a dyncall the note script is executed in a new context which prevents unwanted memory access.
# loop while we have notes to consume
while.true
# execute the note setup script
exec.note::prepare_note
# => [NOTE_SCRIPT_HASH]
# invoke the note script using the dyncall instruction
dyncall
# => [OUTPUT_3, OUTPUT_2, OUTPUT_1, OUTPUT_0]
# clean up note script outputs
dropw dropw dropw dropw
# => []
# check if we have more notes to consume and should loop again
exec.note::increment_current_consumed_note_ptr
loc_load.0
neq
# => [should_loop]
end
When processing a note, new note creation might be triggered. If so, all necessary information about the new note is stored in the output note data in memory.
Info
- The Miden transaction kernel program prevents notes from having direct access to account storage.
- Notes can only call the account interface to trigger write operations in the account.
Transaction script processing¶
If a transaction script is provided with the transaction, it is processed after all notes are consumed. By loading the transaction script root onto the stack, the kernel can invoke a dyncall and in doing so execute the script. The transaction script is then again executed in its own context.
The transaction script can be used to authenticate the transaction by increasing the account’s nonce and signing the transaction, as in the following example:
use.miden::contracts::auth::basic->auth_tx
begin
call.auth_tx::auth_tx_rpo_falcon512
end
Note
- The executing account must expose the
auth_tx_rpo_falcon512function in order for the transaction script to call it.
Epilogue¶
The epilogue finalizes the transaction. It does the following:
- Computes the final account hash.
- If the account has changed, it asserts that the final account nonce is greater than the initial account nonce.
- Computes the created notes commitment.
- Asserts that the input and output vault roots are equal.
There is an exception for special accounts, called faucets, which can mint or burn assets. In these cases, input and output vault roots are not equal.
Outputs¶
The transaction kernel program outputs the transaction script root, a commitment of all newly created outputs notes, and the account hash in its new state.