
- L2 transactions via JSON RPC.
- Transactions stored in the pool DB.
- Trusted sequencer selects transactions from pool DB.
- Trusted sequencer batches and sequences transactions.
Batch pre-execution
The initial step in creating a batch involves verifying whether the chosen transactions align with execution parameters and do not surpass the gas limit. This step is known as batch pre-execution. It is carried out by the sequencer through an executor, as depicted in the figure below.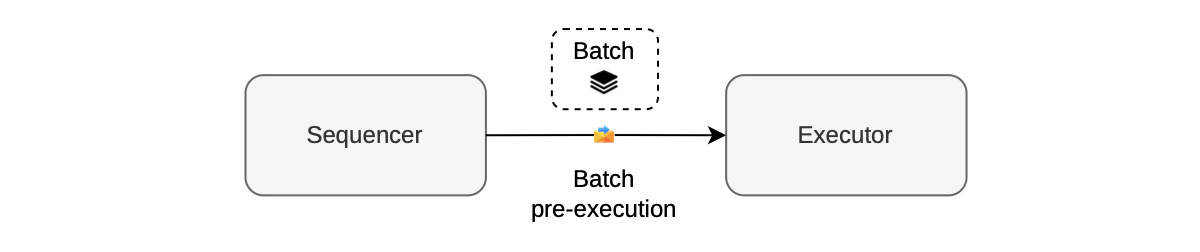
- The execution trace reaches the maximum number of rows.
- The gas used attains maximum gas limit.
- The allocated time expires.
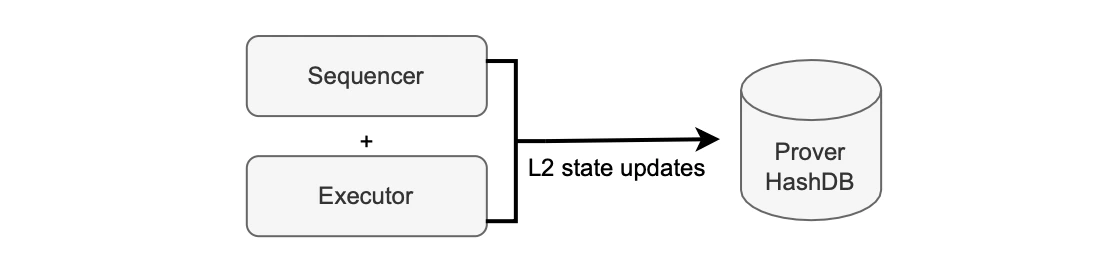
Sending batches to L1
The next step is to send a call to the smart contract to sequence batches. Once a batch is closed, the sequencer stores the data of the batch in the node’s state DB. Then, the looks for closed batches and sends them to the L1 smart contract via the which makes sure the transaction is included in a batch. This process is depicted in the figure below.
- The L2 transactions data, which is an array containing data for each batch. It includes all transactions within the batch along with a timestamp indicating its closure time.
- Additionally, the L2 coinbase address, representing the Ethereum address for receiving user fees.
- Lastly, a timestamp indicating when the L2 transactions were sequenced.
Accumulated input hash pointers
When the smart contract receives a transaction for sequencing into batches, it creates a cryptographic pointer for each batch. These pointers identify a batch and specify its position. Subsequently, provers utilize these pointers as references during the proving process, allowing them to precisely identify the batch being proved and retrieve its associated data. The use of cryptographic pointers ensures a robust and unambiguous link between the sequencing operation and the corresponding batch data for subsequent verification.
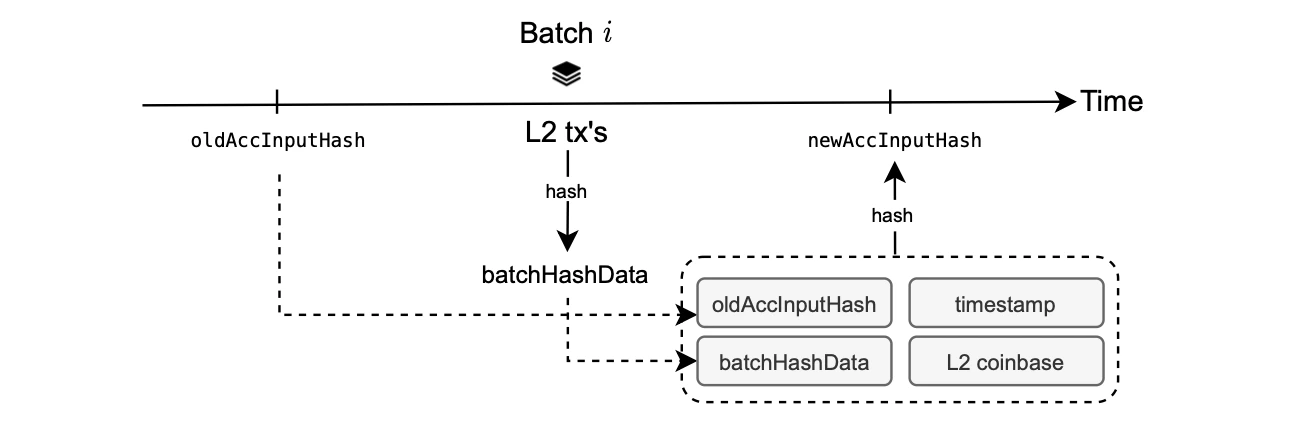
- The preceding pointer.
- The transactions encompassed within the L2 batch.
- The batch timestamp.
- The L2 coinbase.