Padding and the Keccak-F SM
Although the hashing of messages is carried out by the Keccak-F SM, the padding happens in the Padding-KK SM. Messages are presented to the Padding-KK SM as byte-strings in hexadecimal form. But the Padding-KK-Bit SM ensures that these are presented as bit-strings to the Keccak-F SM. Even though Keccak-F SM receives strings of any length as inputs, each input-message to the Keccak-F SM is first split into blocks of 1088 bits (i.e., 136 bytes), called the bitrate (or rate). If the tail-end of the splits is shorter than 136 bytes, or if the original message is shorter than 136 bytes, a specific string is appended to it in order to form a full 136-byte string. The appended bits (or bytes) are referred to as the padding. Keccak’s first padding-rule is to append the string of the appropriate length. That is, the padding always consists of two 1’s and a string of 0’s between them. The second padding rule: If the input-message is exactly 136 bytes long, or a multiple of 136 bytes, then a block of 136 bytes consisting of just the padding , must be appended. It is crucial to emphasise that the Polygon zkEVM follows the Keccak construction used in the Ethereum. So then the Padding-KK SM does not append any other ‘fixed’ bits to the padding, such as appending "" as it is done in the FIPS’s SHA-3. Therefore, as far as the Keccak-F hash function is concerned, the Polygon zkEVM does not follow the FIPS.202 Standard.Input strings and padding
Consider the strings that need to be hashed. Note that the bits (or bytes) of these strings cannot be simply combined and presented as one stream of bits (or bytes) as though they belong to one long string. But each string need to be treated as an individual string, and thus must first be separately padded in line with the above-mentioned padding rules. Only thereafter, depending on the SM involved, can the bytes or the bits be fed into the relevant SM. The idea here is to map each string to one or several blocks of 136 bytes (1088 bits), and include the proper padding at the tail-end part.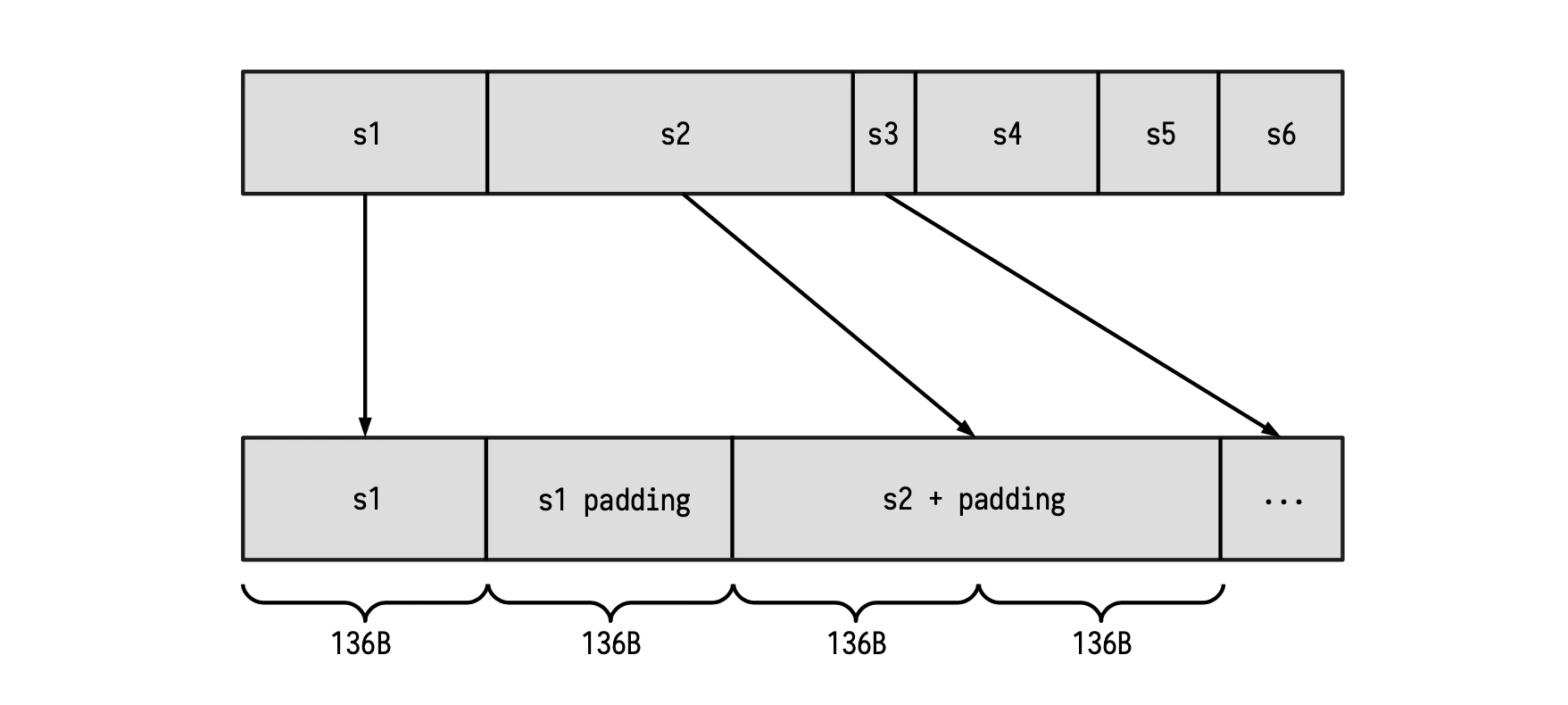
Dealing with Main SM queries
The Padding-KK SM is in charge of validating that the padding rule is correctly performed, as well as validating each of the prescribed operations;- Validate the lengths of given strings . (i.e., length check),
- Validate the hashes of certain strings . (i.e., digest check),
- Validate reads from 1 to 32 bytes of string . (i.e., read check).
Setting up columns for verification purposes
We now design a series of columns that enable us to completely verify correctness of every state transitions.- : This register stores every byte of the padded input (as commented before), one byte per row.
- : This register stores an increasing sequence of integers starting from 0, changing its value at the beginning of a new string. Of course, an address completely determines the corresponding string of a certain byte.
- : This register represents the connection between two blocks. If is 1, the actual block is in the same string with the previous block. Otherwise, the last block is in the previous string.
- : This register flags the last row of every block. If is 1, the next block starts in the next row of the table.
- : For each string, this register is a decreasing sequence of signed integers. Starting at the length of the current string and it keeps decreasing until the last block of the string is reached. Observe that this value can be negative since a padding may be present in the string. ( is short for ‘remaining’.)
- : For each string, this register stores original length (i.e., the length of the string before padding was appended). Therefore, this register remains constant for all rows of each string. Observe that, at the first row of each string, coincides with .
- : A computed register which is 1 whenever is zero, and 0 otherwise.
- : The register is 1 just after the byte , corresponding to the appearance of padding bits. Observe that it can happen that is constantly 0 among a full string. This is because we can have the situation where the padding only consists of the byte .
- : This register is actually computed from the registers , and as follows,
Example: Padding check using columns
Let us illustrate this design with a table, using the columns defined above. Suppose the following strings have been padded and are ready for hashing: where ”|” indicates the end of a 136-byte block. In the below table, these 136-byte splits between blocks are indicated with a horizontal line. The above table illustrates how the columns can be used to record the executional trace of the Padding-KK State Machine. As it is our general approach, a strategy towards achieving verifiable computations, the next task is to describe the state transitions of the Padding-KK SM in terms of polynomials.Description of state transitions in PIL
By capturing the relationships between and among the columns (registers defined above) in terms of equations, amounts to translating the execution of the padding into a verification code written in PIL.- In order to guarantee that the value recorded in the register decreases until is 1 (that is, the end of the string), use the relation,
- How can we validate the fact that was constructed as expected?
- Verifying correctness of the register requires two constraints;
- When is 1 and is 0 : in this case, the next value of should be 0, because of the block change but within the same string.
- When both and are 1 : in this case, the next value of should be 0, due to the string change.
- The register is constant within each string. It must therefore satisfy this relationship,
- Checking that and coincide at the first state of each string, use the constraint, where is a committed column and it is such that . In fact, is a shifted version of , which is used to ensure that, when starting a string (and therefore, ), then .
- Let us now specify the relations that satisfy the register. As commented on before, is constant within each string. Hence, if and only if . The constraint for the register is therefore, Note that going from one string to the next, the values of the register form an increasing sequence (increasing by steps of 1 from one string to the next). However, since the polynomials utilized in this scheme are all cyclic (due to evaluations on roots of unity), there is a need to ensure that the register resets to whenever the reading returns to the first row. For this purpose, a register called is added. And is 1, if is 1 and the string, that the last block belongs to, is not the last one. Similarly, another register called is added, and it is defined such that See below table for a comparison between the and non- registers.
- In order to grapple with the increasing but cyclic sequence of , the following constraint is used,
- Now, checking whether is 1 if and only if is 0, is done reversely by first committing the column , the inverse of , and computing as: And then, as usual, check the relation, .
-
Next is the register which stores the input byte if and only if the current row does not corresponding to the padding. is computed from the , and registers. This ensures loading the padding bytes at their correct positions.
In fact, this register is used in the Plookup of the next state machine.
Observe that can be computed as
Let us carefully analyze this equation:
- If , and are all , then equals . As mentioned above, at the non-padding rows, we just store .
- If is 1, is 0 and is 0, then equals , which is the first byte of the padding.
- If is 0, is 1 and is 0, then equals , which are the intermediate bytes of the padding.
- If is 0, is 1 and is 1, then equals , which is the last byte of the padding.
- Lastly, we should consider the special case where the padding is only the byte . In this case, is 0 at the last row meanwhile and are both 1. Therefore, equals , as we wanted.
Hash output check
We have thus far only dealt with correct inputs of the padding. Now, we introduce several columns to deal with the hash itself. Since KECCAK-256’s output is 256 bits long, we use eight (8) registers each of 32 bits to store the result of the hash function. Denote these registers by . As columns, these registers remain constant within a single string, because they represent the hash of a given string. The following constraints are therefore added, A combination of other KECCAK-related state machines is used to verify correctness of the output hash. The reason for this is that, for compatibility with the KECCAK-256 hash function, we first need to describe all inputs in terms of bits.Length and read check operations
In this section we give a description of the design that allows us to verify the lengths of input strings and the read operations.Length check
The length check is almost trivial because the register has already been introduced. Suppose one is given a length and an address . And the aim is to check if the string corresponding to the address has length . The strategy is to use Plookup to verify that the given table contains a row with and an address in the last row of the string (i.e., when ). That is to say, the table of columns; , and ; is as displayed in the table provided below. The PIL code for this Plookup looks like this: where flags whenever the operation is checked and the length is stored in .Read check
Checking reads requires more columns to be introduced. Recall that, given three parameters;- the address of a string,
- the position of the starting byte of the string, and
- the total number of bytes that we want to read.
- : A register that specifies the number bytes to be read. It is a number register, containing numbers between 1 and 32, and it remains constant in each of the readings we want to perform.
- : A decreasing sequence of values, starting from the length value of the read minus 1 (i.e., ) and ends at 0, for each read. This is important for positioning each byte at the correct power of 2.
- : This is a computed column, using the same inverse technique as before. It records instances when the register is 0. First, the register is committed, allowing to be expressed as