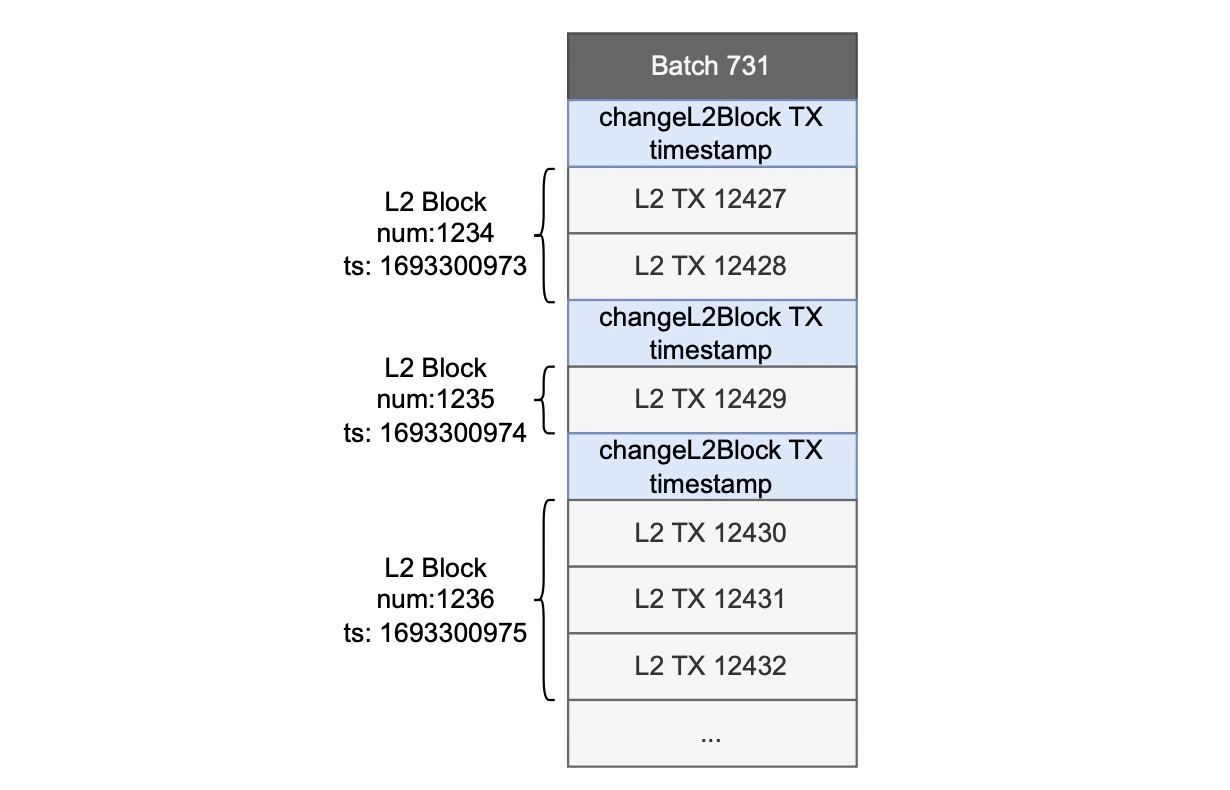
- An L2 block is defined to contain only one transaction, resulting in as many blocks per batch as there are transactions.
- Timestamps are not assigned to blocks but to batches, which means each batch typically contains more than one block.
- It leads to a bloated database due to the large number of L2 blocks created.
- It causes breaks in dApps that are configured with block-per-timestamp settings, as they rely on timestamps for proper timing of smart contract actions.
changeL2Block.
The figure below displays the Etrog block structure within a batch.
The 0x5ca1ab1e smart contract
Starting from the proving system’s point of view, recall that,
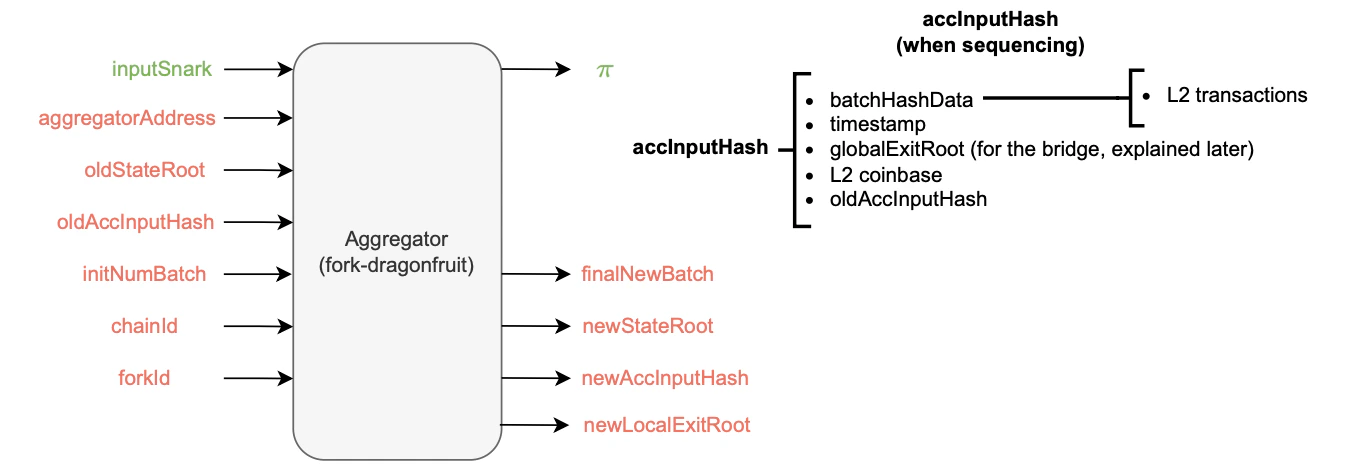
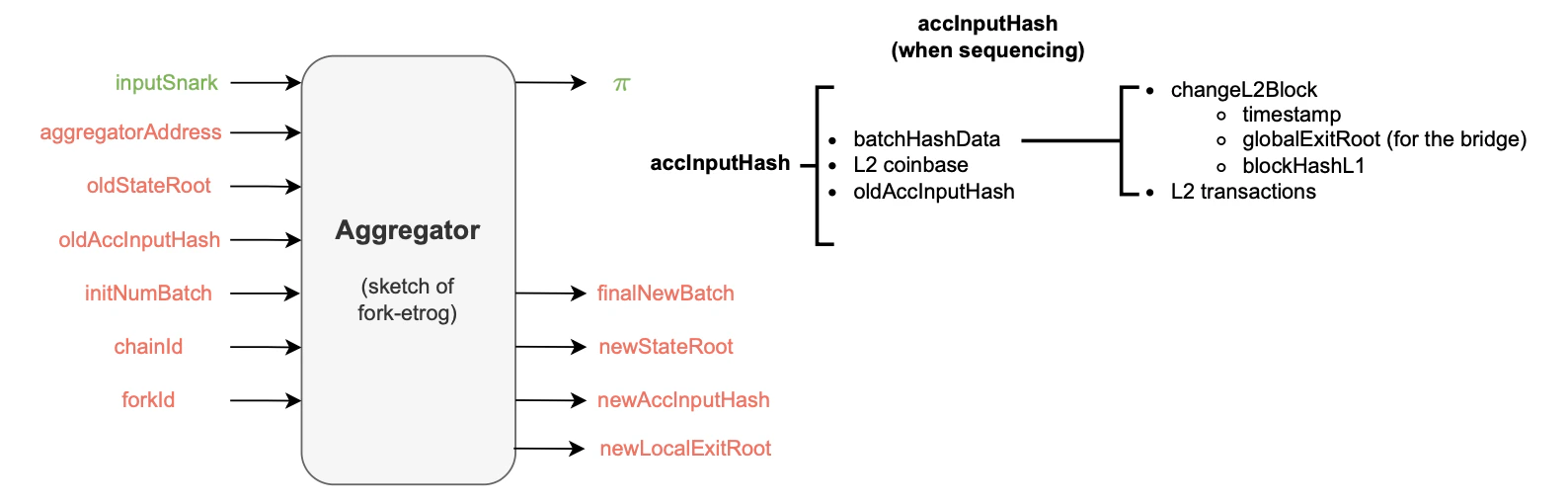
- The aggregator receives several inputs, such as the , and .
- The accumulated input hash is a recursively computed cryptographic representative of several batch data, including the hash of all the L2 transactions within previous batches and the last batch’s sequencing timestamp. Also, due to its recursive nature, the incorporates the previous accumulated input hash as part of its hashed data.
0x5ca1ab1e.
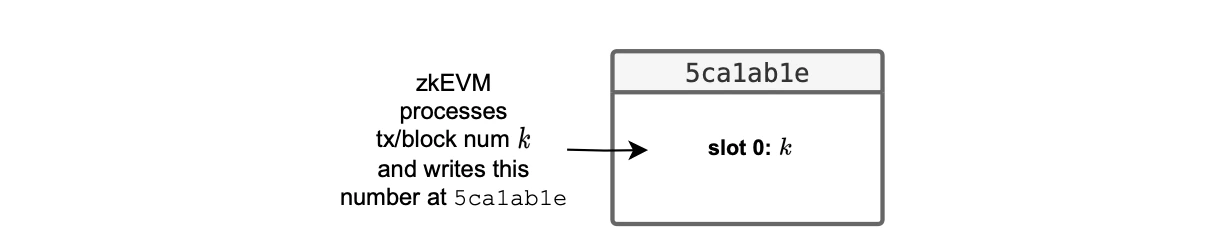
After processing a transaction, the ROM writes the current block number into this specific storage location.
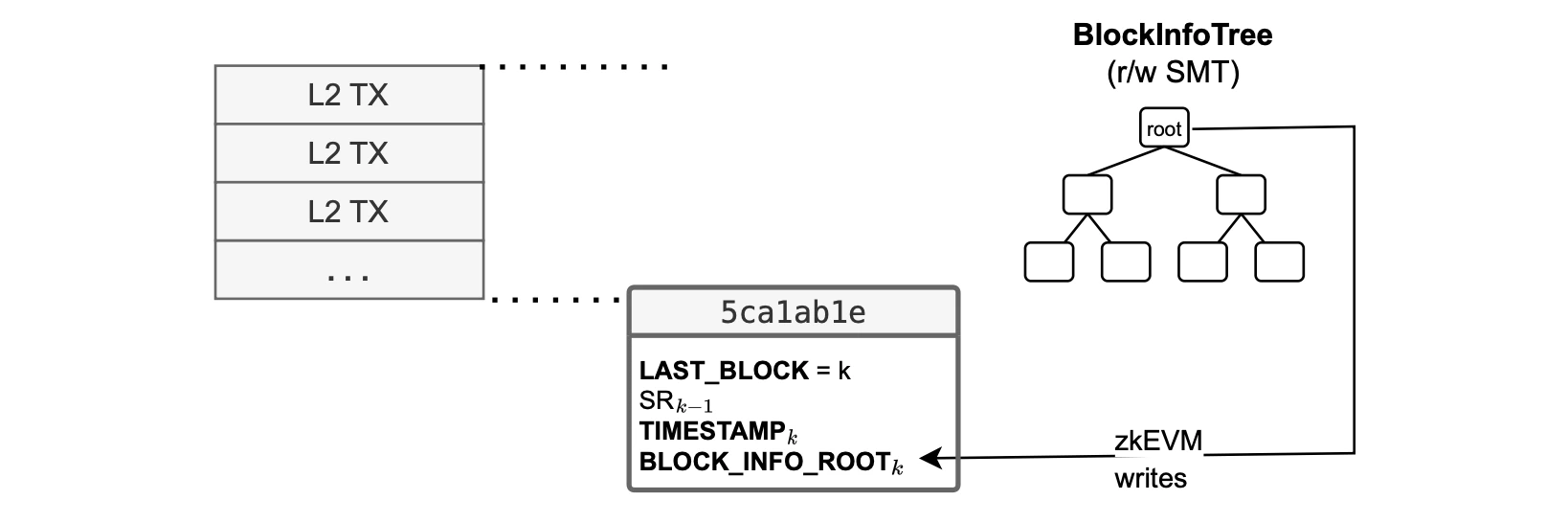
As depicted in the figure below, the L2 system smart contract deployed at address 0x5ca1ab1e stores the number of the last processed block at slot 0.
Henceforth, during each batch processing, the system records all block numbers it contains.
0x5ca1ab1e is frequently referred to throughout this document, we call it by its address. i.e., We refer to it as the 0x5ca1ab1e system smart contract.
The BLOCKHASH opcode
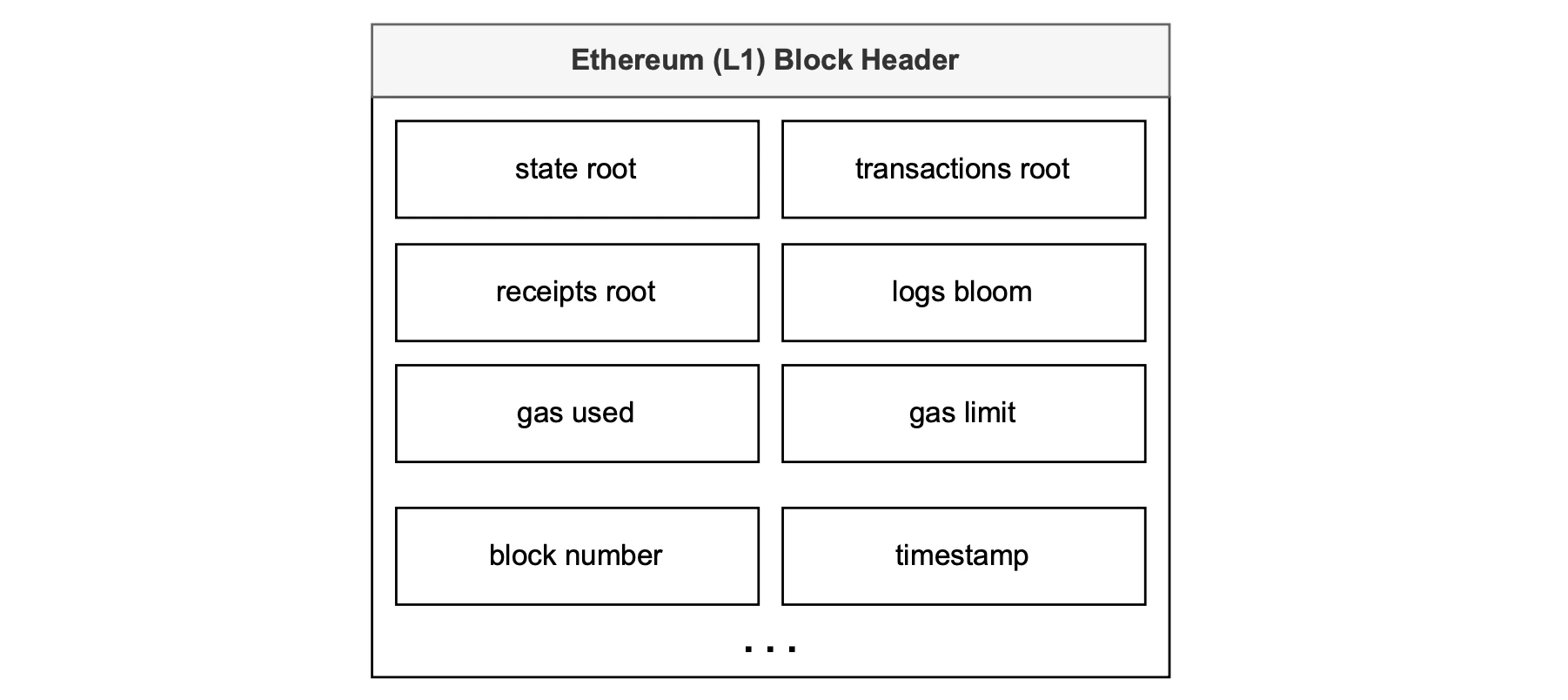
In the EVM, the BLOCKHASH Opcode provides the keccak-256 digest of the Ethereum L1 block header, which includes: root of the state trie, root of transactions trie, root of receipt trie, logs, gas used, gas limit, block number, timestamp, etc.
A complete list of all parameters stored in an Ethereum block and block header is given in the Ethereum organisation documentation.
You can use the Geth library to compute an Ethereum block hash.
See the figure below for an example of an Ethereum L1 block header reflecting some of these parameters.
zkevm_getFullBlockByHash which, given its Ethereum-like block hash, retrieves a block with additional information.
Dragonfruit (ForkID 5)
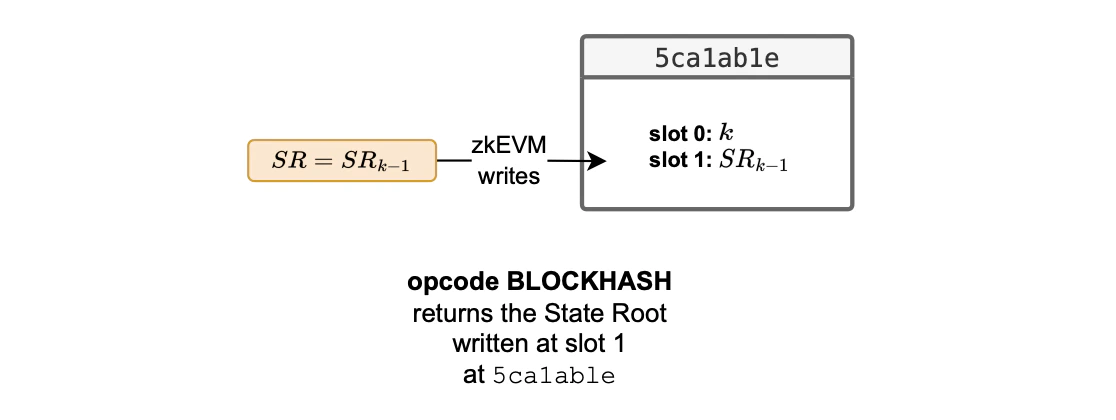
Following Ethereum’s philosophy, there is a need to keep track of every state change between blocks. In the Dragonfruit setting, this is equivalent to tracking state changes per transaction. For the sake of security, all the state changes must be accounted for. Polygon zkEVM therefore stores the state root after processing each transaction. In each case the state root is stored in a designated slot: The slot 1 of the0x5ca1ab1e smart contract, as illustrated in the figure below.
With this approach, the state root is stored for each transaction within a batch, allowing for precise monitoring of the entire batch processing at the transaction level.
L2 BLOCKHASH
In the ForkID 5 context, the L2 BLOCKHASH opcode provides only the state root when executed by smart contracts. We define this particular output of the L2 BLOCKHASH opcode as the native block hash, and provide the state root accessing the0x5ca1ab1e smart contract.
L2 system smart contract 0x5ca1ab1e stores the last state root , after processing a block, at slot 1.
0x5ca1ab1e.
Processing L2 blocks
The question is: When to write the state root in the0x5ca1ab1e system smart contract?
Consider the figure below for a schematic diagram of how the new state root is updated and written in the 0x5ca1ab1e system smart contract when processing L2 blocks.
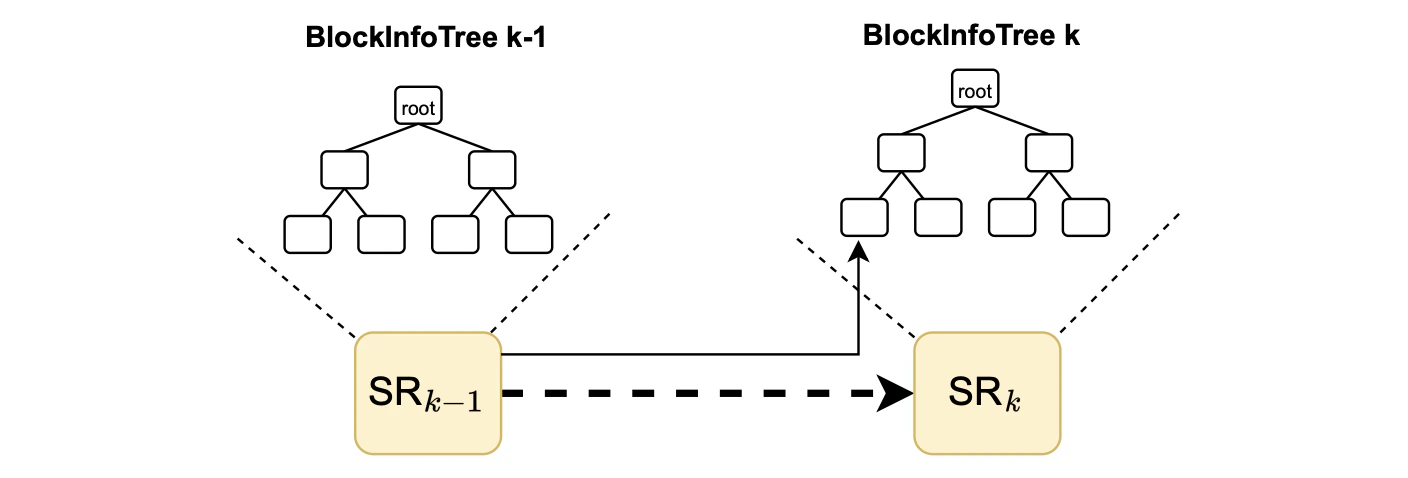
Firstly, denote the last block among the completely processed blocks of a batch by .
And hence denote the state root at this point by .
After completing the processing of the last block , the zkEVM updates the slot 1 of the 0x5ca1ab1e smart contract with the current state root.
But since updating a storage slot of an L2 smart contract actually changes the L2 state, it leads to a new state denoted by .
At this point, we start processing the new batch.
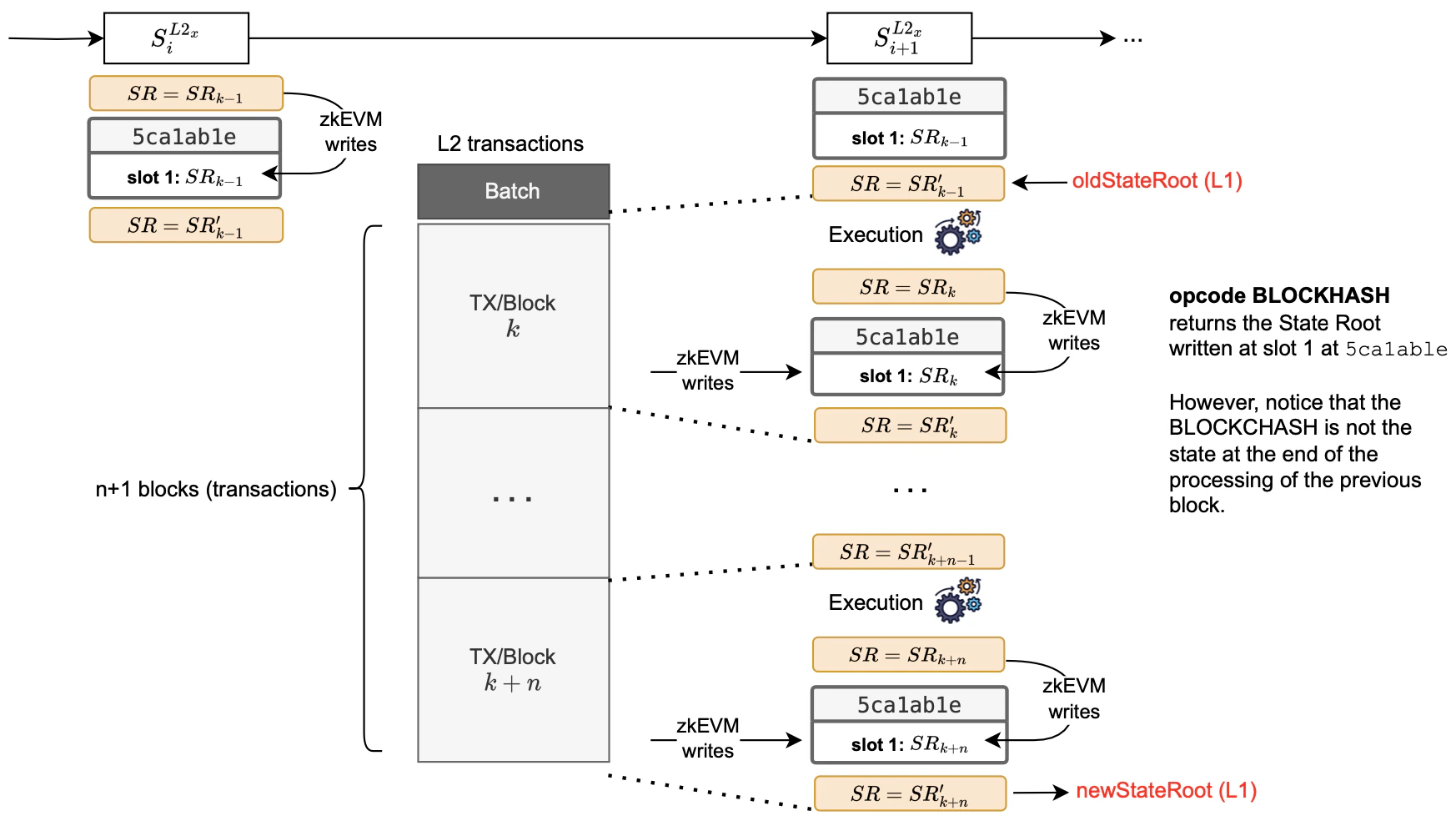
0x5ca1ab1e contract and starting to process any new block) and the state root do not match.
Yet, when the new block is executed, the state root becomes . And, upon writing the state root to the 0x5ca1ab1e contract, the state root becomes .
This pattern continues with subsequent blocks.
Therefore, it can be misleading to rely on the state root stored at slot 1 of the 0x5ca1ab1e contract as the representative of the L2 state (i.e., The root of the state at the end of the execution of the previous block) because the actual corresponding state root is the state root after updating the contract.
Consequently, in the Dragonfruit upgrade, the value obtained when BLOCKHASH is called is not precisely the same state root obtained just before the execution of the new block begins.
This mismatch issue is addressed in the Etrog upgrade.
L2 native vs. L2 RPC Ethereum-like BLOCKHASH
In Ethereum, the block header is secure because it is computed and validated by all the nodes within the network.
However, in the Polygon zkEVM, the prover is the only entity responsible for proving that the parameters related to block execution are correct, and these parameters form part of the state.
Ethereum takes the approach that block parameters, providing information about execution of transactions in each block, are hashed to obtain the block hash.
And, the resulting state root is one of these parameters.
Since the aim is to prove that the block hash computation and its parameters are correct, the native block hash in the Polygon zkEVM context has to be the L2 state root.
The zkEVM prover is in charge of proving that the changes in the L2 state root are correctly performed.
So, if we want to provide a verifiable proof of the execution parameters of a block (such as gasUsed, transaction logs, etc.,) we have to work these parameters into the Polygon zkEVM processing, including them in the L2 state.
Incorporating block execution parameters into the L2 state is facilitated through the 0x5ca1ab1e smart contract.
Thus, the L2 state root is a hash that contains all the parameters that provide information about block execution.
The figure below depicts the differences.
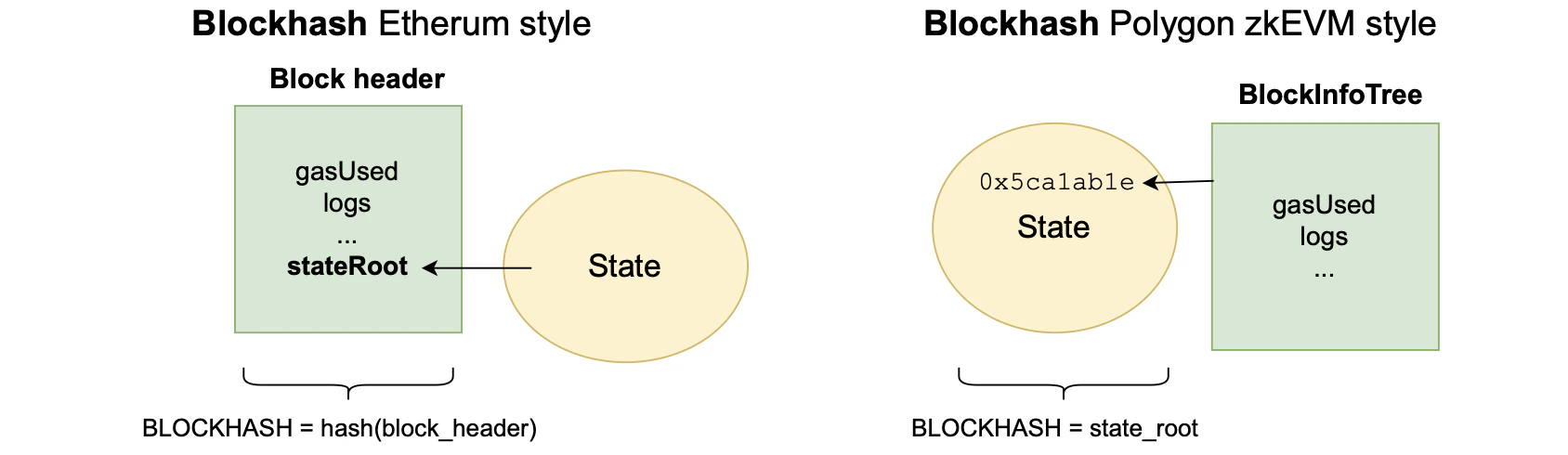
- As part of the block execution, zkEVM-specific parameters like each transaction’s is included.
- Poseidon hash function is used instead of Keccak-256.
- Transactions data is hashed with linear Poseidon.
zkevm_getNativeBlockHashesInRange returns the list of “native block hashes”. That is, the list of L2 state roots.
Etrog upgrade (Fork-ID 6)
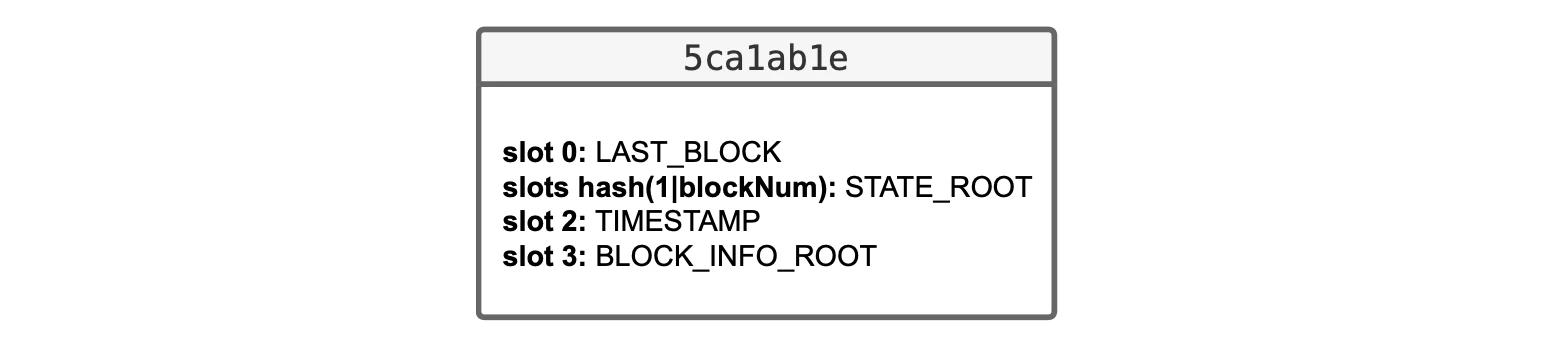
In the zkEVM Etrog, similar to the Ethereum setting but not identical, additional data related to the L2 block processing is secured via the0x5ca1ab1e smart contract.
In particular, the L2 system smart contract 0x5ca1ab1e stores, in:
- Slot 0: The block number of the last processed block, as in the Dragonfruit upgrade.
-
Slots
hash(1|blockNum): These slots are encoded as Solidity mappings, to store all state roots indexed per block number. - Slot 2: The timestamp of the last processed block, because now we have a timestamp for each block.
-
Slot 3: The root of a
Read-WriteMerkle tree called , which contains information about the execution of the last processed block.
0x5ca1ab1e contract storage in the Etrog upgrade.
BlockInfoTree
Next we describe the , together with its contents, keys, and values. The is aRead-Write Merkle tree containing information about the execution of the last processed block.
Observe that the is unique for each block.
Contents
The stores the specific data associated with each transaction, simply referred as the transaction data, and denoted by . So, is an array of data: But each L2 transaction’s data is stored as its cryptographic representation as follows: The field is actually computed from the transaction’s signature using ecRecover. Each executed transaction includes a byte parameter called , which is specific for Polygon zkEVM. This parameter is also stored in the . The also stores the following data, coming from L2 transaction execution:-
Data stored in or updated from the L2 state, obtained from the
0x5ca1ab1esmart contract: – (i.e., The previous L2 state root). – . -
Data from each L2 block, obtained from L1 as the proof input:
– from the
changeL2blocktransaction. – for the bridge. – , which is the L1 block hash when theglobalExitRootparameter was recorded by the L1 contractPolygonZkEVMGlobalExitRoot.sol. In Solidity, this is done using: . - Data from the data of sequenced batches obtained from L1 as the proof input: – .
- Data computed from the block execution: – .
- Other parameters: – . Although infinite, a single transaction is limited to a maximum of 30M gas in the zkEVM.
Keys and values
How to store all previous block-related and transaction-related data in the ? The , being unique to each block, operates as aRead-Write sparse Merkle tree and functions similar to the L2StateTree key-value structure.
It’s also constructed using the Poseidon hash function.
The keys utilized to position each data piece within the tree are also derived by applying the Poseidon hash function.
The output of the Poseidon hash function is given by:
\begin{aligned}
&\mathtt{\big(out[0], out[1], out[2], out[3]\big)\ } \\
&\mathtt{\ = Poseidon\big(c[0], c[1], c[2], c[3]; in[0], in[1], in[2], in[3], · · · , in[7]\big)} \)
\end{aligned}
where for , each is a capacity element, and is an input element. Also, each Poseidon parameter is a field element in the Goldilocks field where .
Block-related data
When computing keys of block-related data, the Poseidon function is used as follows: where is fixed to the value (i.e., ) and is used to distinguish different block-related data as listed below:- , for the previous block hash.
- , for the coinbase address.
- , for the block number.
- , for the gas limit.
- , for the block timestamp.
- , for the Global Exit Root.
- , for the L1 block hash.
- , for the gas used.
Transaction-related data
When computing keys of transaction-related data, the Poseidon function is used as follows: where the transaction index is hashed within the block, and takes any of the following values:- , for the transaction data hash.
- , for the transaction status.
- , for the transaction cumulative gas used.
- , for the transaction logs.
- , for the transaction’s effective percentage.
Processing L2 blocks
How are L2 blocks processed in the Etrog upgrade? The diagram below is useful in explaining the process.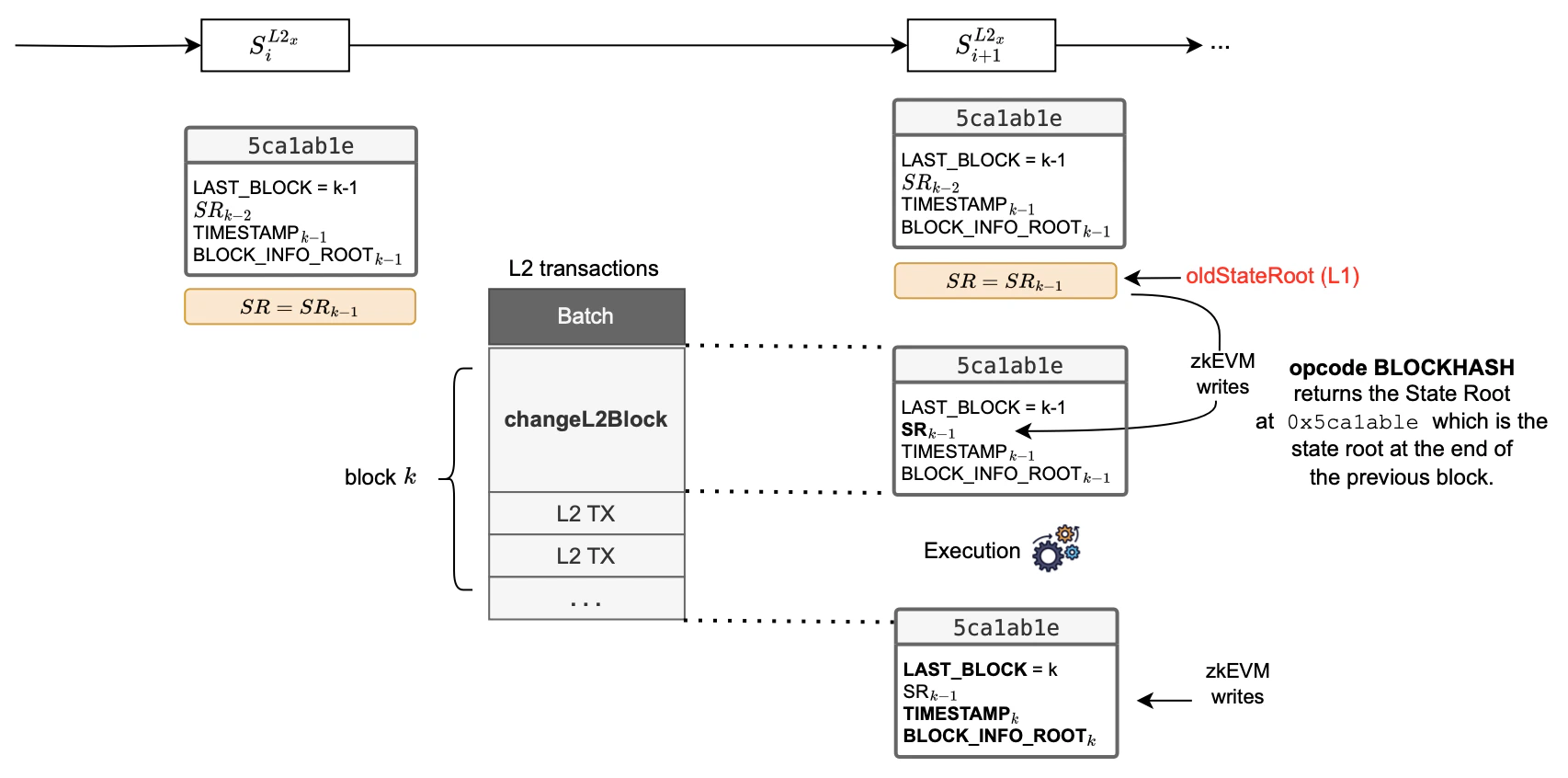
0x5ca1ab1e smart contract stores four parameters:
with the state root still reflecting the root corresponding to block .
Next, the system starts processing a new block, which starts with the changeL2Block transaction, as the first transaction to be processed in a block.
The proving system provides the , and the initial step of processing a block in the ROM is to record it in the 0x5ca1ab1e smart contract.
Subsequently, and in contrast to what happened in Dragonfruit upgrade, every transaction containing the BLOCKHASH opcode now provides the correct state root, .
As shown in the figure below, while transactions within the block are processed, the zkEVM not only updates the L2 state but also adds the information to the .
Upon completing the execution of the block, the root of this tree is written into 0x5ca1ab1e.
When executing all transactions within the block, the 0x5ca1ab1e contract is updated again.
And the whole process is repeated.