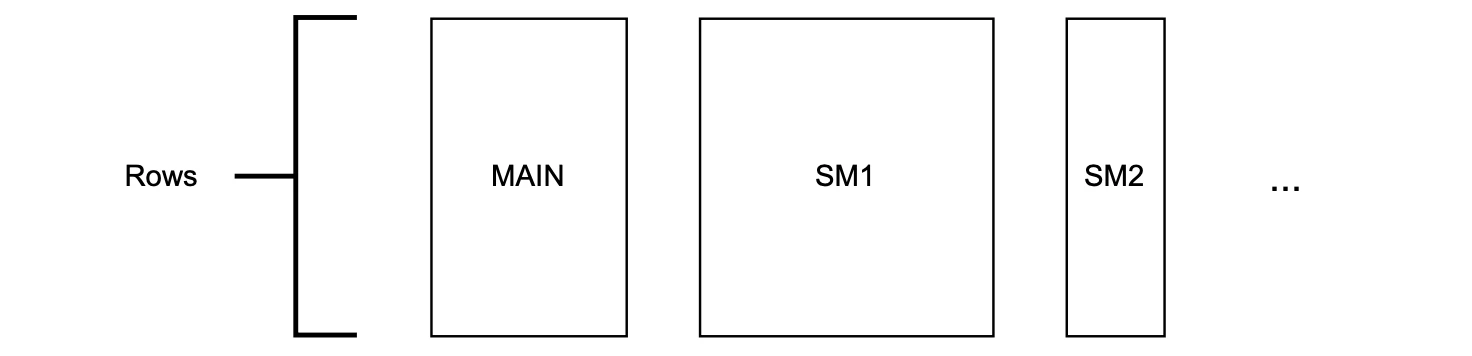
- Column A represents the base, and it is defined by .
- Column B stores the decreasing exponent, so .
- Column C stores the intermediate results. That is, ,
Linking execution traces via lookup arguments
Let us now explore how the above-mentioned approach, regarding having the main execution trace which is linked to secondary execution traces, actually works. We continue with the EXP example, where only two execution traces are considered:- The main execution trace and
- A secondary execution trace especially created for the EXP operation.
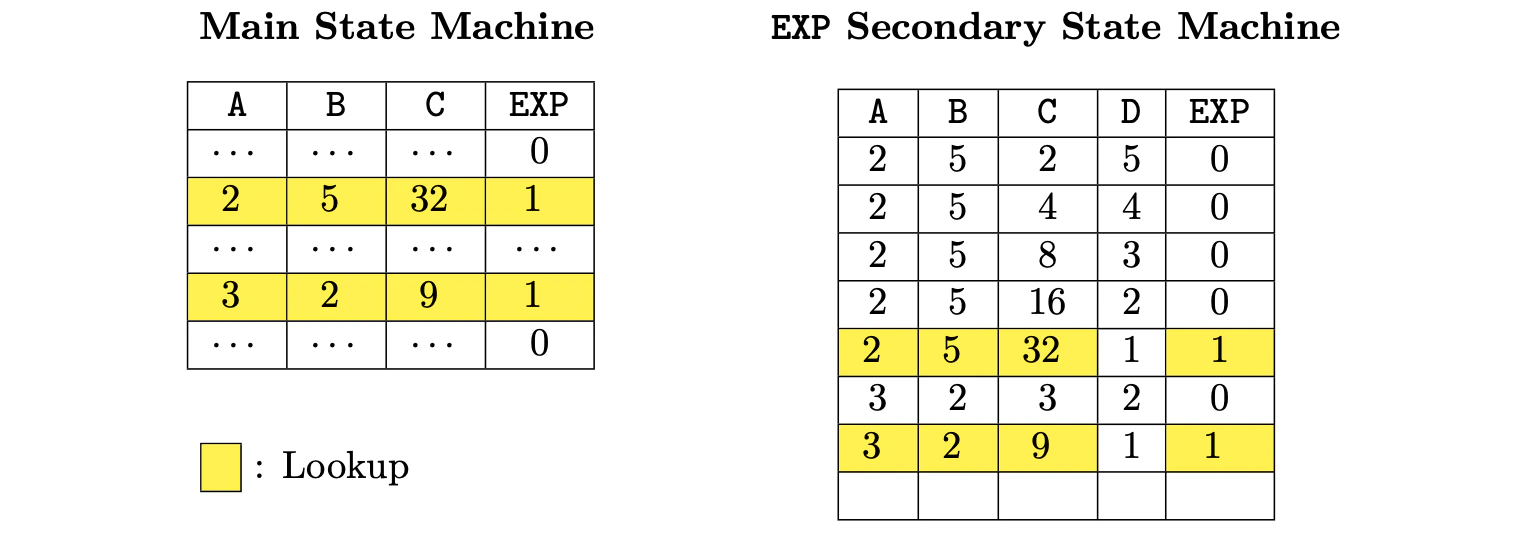
- Column A represents the base. Observe that this column is allowed to contain several values as we may check several EXP operations in the same state machine for as long as we do not consume more rows than the fixed maximum.
- Column B stores the exponent.
- Column C stores the intermediate results.
- Column D stores a decreasing counter. In each EXP operation, it starts with the same value as the exponent and keeps decreasing until arriving 1, meaning that the current operation has been finished.
- The EXP column flags when the operation is actually finished. Rows with EXP equal to 1 are the ones where we can state consistency of EXP operations of the main state sachine via a lookup argument.
binary.pil, that is responsible for constraining binary operations (such that additions of 256 numbers represented in base 2 and equality/inequality comparators), or mem.pil, which is responsible for managing memory-related opcodes.
The Main State Machine is constrained in the main.pil, which serves as the main entrypoint for the whole PIL of the zkEVM.
Final remarks and future improvements
The columns of each state machine are defined by the design of its corresponding execution trace. Due to constraints in our existing cryptographic backend, it is mandatory that all state machines share the same number of rows. The computation of an L2 batch can have branches and loops and hence, each L2 batch execution can use a different number of operations in the zkEVM. Consequently, the number of rows utilized by each state machine depends on the specific operations carried out during batch execution. Since the number of rows is fixed (and the same for all state machines) we can have unused rows. But, what is more important is that obviously, the size of the computation being proved must fit in the execution trace matrices available