Keys and values
The Polygon zkEVM state is stored in a key-value format within a special Merkle tree known as a _Sparse Merkle Trie_ (SMT). This tree is binary and fully updata
The Polygon zkEVM state is stored in a key-value format within a special Merkle tree known as a Sparse Merkle Trie (SMT). This tree is binary and fully updatable, supporting both Read and Write operations.
Similar to the use of Merkle Patricia tries in Ethereum, an SMT is a data structure designed to retrieve a value by traversing a branch of nodes that store associated references, called keys, which together lead to a leaf containing the value.
Underlying Hash Function
Since Polygon zkEVM is a zk-rollup, a ZK-friendly hash function is the most suitable for constructing SMTs.
The Poseidon hash function, designed to address some of the challenges and limitations of traditional hash functions in implementing ZK-proofs, was a natural choice.
Readers interested in cryptographic details should refer to the sponge construction document for Poseidon's basic design structure and the Poseidon state machine document for its internal mechanism.
We henceforth consider an instantiation of Poseidon over the Goldilocks field where .
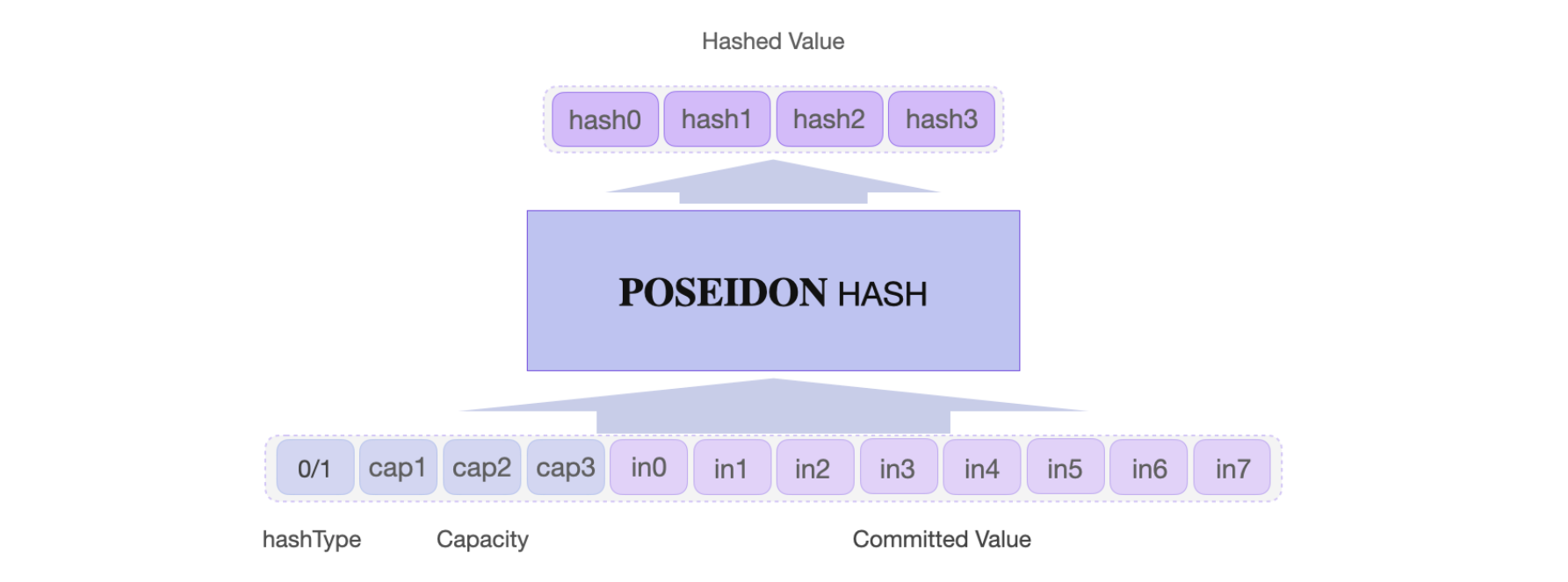
Poseidon inputs and outputs
Observe that Poseidon's input and output elements are represented as arrays.
The Poseidon hash function accepts a full input consisting of 12 field elements: an array of 4 capacity elements and an array of 8 input elements, with each input element being a 32-bit field element.
The output is an array of 4 field elements, each approximately 64 bits long.
Refer to the figure below for a simplified diagram of Poseidon's input and output arrays.
Poseidon hash types
To safeguard SMTs against second-preimage attacks, two instances of the Poseidon hash function are utilized:
Referring to the figure above, the hashType is indicated by the first element, , of one of the following two arrays:
That is, .
When constructing an SMT, the Poseidon hash with is used to create branch nodes, while is used for leaf nodes.
Example (hashType)
Denote a Poseidon hash as follows:
where is an array of 4 field elements and is an array of 8 input elements of the hash.
Using this notation, the two instances of the Poseidon hash function are:
-
corresponding to , and used for branch nodes.
-
corresponding to , and used for leaf nodes.
Constructing an SMT
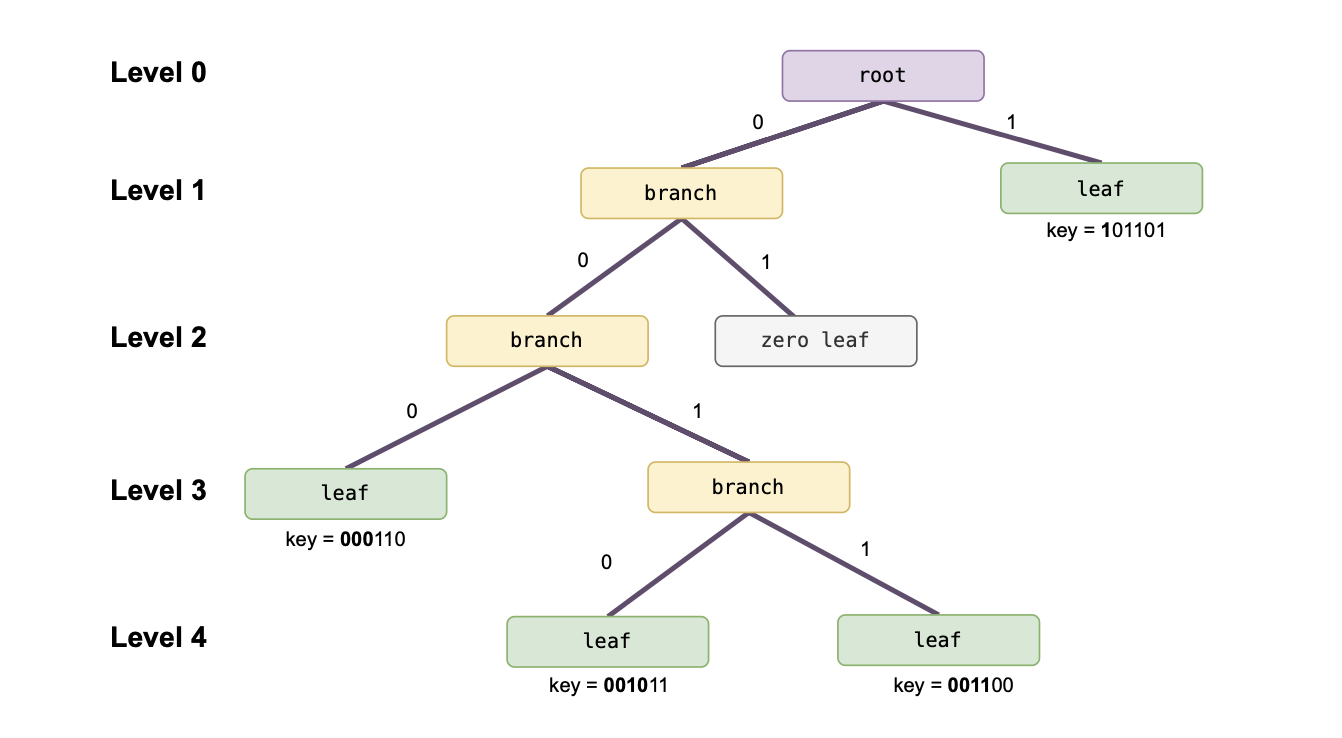
Let’s use an example to visualize how an SMT is constructed.
Suppose a given SMT has values stored at leaves associated with the following four keys:
Firstly, note that by non-zero leaves we refer to leaves storing some data. Hence, a zero leaf refers to a leaf node that carries no data.
Secondly, when constructing the SMT corresponding to these 4 keys, the key-bit represents an edge to the left, while the key-bit means an edge to the right.
This means, non-zero leaf nodes share paths for as long as their associated keys have common least-significant bits.
Therefore, any pair of keys associated with distinct non-zero leaves must differ in at least one of the key bits.
This means that prefixes (short bit strings formed from consecutive least-significant key bits) can be used to accurately position non-zero leaf nodes.
Now, based on the keys provided above, there are four distinct prefixes:
Observe that:
-
The path to the leaf associated with differs from the other three paths in the very first edge from the root, which is the edge to the right.
Assuming there are no other non-zero leaf nodes, the corresponding leaf is therefore positioned at the first child node of the root, along the edge to the right.
-
Since the prefixes share the first two bits , the paths to the associated leaves coincide only for the first two edges from the root, both of which are to the left.
-
The prefix differs from the other two prefixes ( and ) at the third bit.
Hence, assuming there are no other non-zero leaves, the leaf associated with is positioned at the third child node, at the end of the third edge from the root, following three consecutive left edges.
-
The last two prefixes ( and ):
Share a common third key bit , so the paths to their associated leaves coincide up to the third edge, which is to the right.
Only differ at their fourth key bits, meaning the fourth edge of the path to the leaf associated with is to the left, while the fourth edge of the path to the other leaf is to the right.
Again, assuming there are no other non-zero leaves in this SMT, each these two non-zero leaf nodes (associated with prefixes and ) is positioned at the end of the fourth edge from the root.
The figure below depicts the SMT containing the four non-zero leaves associated with the given keys: , , and .
Node types
As depicted in the figure above, a typical SMT has four types of nodes: leaf, root, branch, and zero nodes.
-
The leaf node encapsulates the actual data associated with a key.
The data is captured in the form of a hash digest of the key-value pair.
And, due to Poseidon's cryptographic properties such as collision-resistance, anyone can use a Merkle proof to verify if indeed certain data is stored in a particular leaf of the SMT.
-
The root node is the highest node in an SMT, the sole node at level zero, connecting all branches and leaves.
It's the starting point for traversing down the tree structure.
As a hash that includes hashes of all data captured in the SMT, the root serves as the cryptographic summary of the entire dataset and thus acts as a fingerprint of all the values stored in the SMT.
-
A branch node refers to any intermediary node that lies between the root node and leaf nodes, between the root node and other branch nodes, or between a branch node and leaf nodes.
Branch nodes are therefore positioned at various levels in an SMT, and store hashes derived from concatenating two hashes of their child nodes.
The hash at each branch node cryptographically encapsulates the data contained in the subtree (all its child nodes, grandchild nodes, including the leaf nodes) that has the branch node as its root node.
-
A zero node does not represent a zero hash value associated with a specific key, but instead denotes a branch node with no subtree beneath it.
These type of nodes exist whenever two conditions are satisfied:
-
No key associated with non-zero values stored in the SMT has a prefix that leads to the node.
-
The node has a sibling node, which is either a non-zero leaf or a branch node with a non-zero leaf as its child or grandchild.
Referring to the above example, the node reached by traversing the 2-edge path is a zero-node because:
Firstly, none of the keys (, , and ) has as a prefix.
Secondly, the sibling node reached by traversing the 2-edge path has 3 non-zero grandchild nodes in its subtree.
-
Keys and values
The aim with this subsection is to provide an understanding on how the L2 state is managed in terms of the key-value data within SMTs.
As seen above, keys are crucial in positioning values, as well as traversing SMTs to locate these values.
Leaf nodes serve as the endpoints of the tree and essentially hold data.
Next, we provide details on the derivation of keys and the computation of values.
Deriving keys
We begin by describing how keys are derived from their associated leaf data.
Node key is computed as follows:
Each of the four arguments is described below:
-
The address consists of -bit segments representing the Ethereum address associated with the leaf, having 160 bits in the EVM:
-
The SMT key is a single field element, , indicating which of the following five L2 state information is being stored:
-
: for the account balances.
-
: for the account nonces.
-
: for the smart contract code.
-
: for the smart contract storage.
-
: for the smart contract length.
-
-
The hash of the capacity array, called , is computed in one of two ways, depending on whether the stored data is a storage slot or some other type of data.
(a) When storing data that is not a storage slot, is computed as follows:
where capacity is shown as , but it's in fact an array of field elements, each set to .
Since a single smart contract’s address can have multiple storage slots, a key is created for each slot.
(b) For each storage slot, is computed with a specific as follows:
where is an array of field elements each constrained to 32-bit values representing storage slot identifiers, which in the EVM have a size of 256-bits.
Computing values
We now explain how the values stored within leaf nodes are obtained.
The current methodology for hashing the leaf data to derive the leaf node’s value is as follows:
The first argument is the capacity set to , which is actually an array of 4 field elements: .
The second argument, , is an array of 4 field elements representing the remaining key associated with the leaf node.
The third argument, , is an array of 4 field elements calculated as follows:
where is an array of 8 field elements, each restricted to a 32-bit length.
The 32-bits values in the array are computed differently, depending on the type of the data stored in the tree.
-
For , and .
In the EVM, , and are of 256 bits. So, their are computed as expected:
where each input (, or ) is an 8 field element array, each constrained to 32-bit values.
-
For smart contract bytecode.
The hash of the smart contract bytecode is also stored in the L2 state tree.
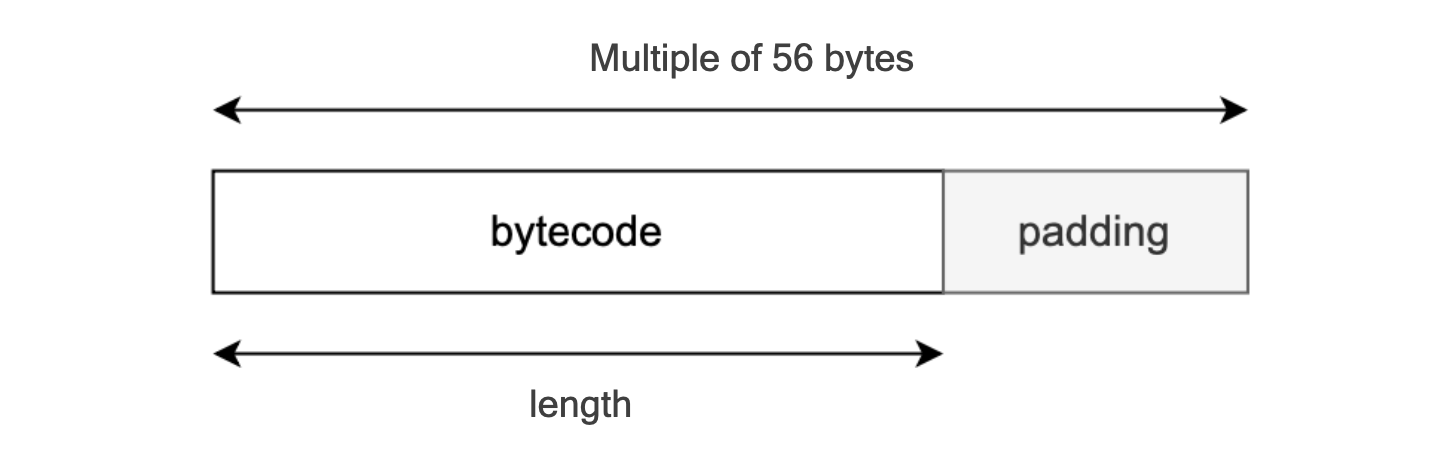
However, since bytecode has an arbitrary size, it can exceed 256-bits (32 bytes).
To manage this issue:
Firstly, padding is used to adjust the size of the input bytecode to a suitable multiple, in particular, a multiple of 56 bytes.
Secondly, the resulting padded byte string is linearly hashed.
-
For bytecode length.
The length of the actual bytecode is stored in the L2 state tree, because it is necessary to distinguish between payload and padding.
The bytecode length which is the number of bytes forming the bytecode, is hashed as follows:
-
Input bytecode encoding.
We encode the bytecode in segments of 7 bytes (56 bits), which is the biggest amount of bytes that can be represented with an element of the Goldilocks field:
Since the input values of the Poseidon hash function is an array of 8 field elements, the total input is encoded as of bytecode.
-
Padding procedure.
The padding procedure used to adjust the original bytecode string to a padded string, that's a multiple of 56 bytes, is as follows:
-
Add the byte at the end of the original bytecode.
-
Fill with zeros until the padded is multiple of 56 bytes.
-
Add as the last byte.
-
-
Example (Bytecode hashing)
Suppose the 2-byte, , is the original bytecode.
The padded bytecode becomes:
a string of 56 bytes.
-
Recursively chained hashing.
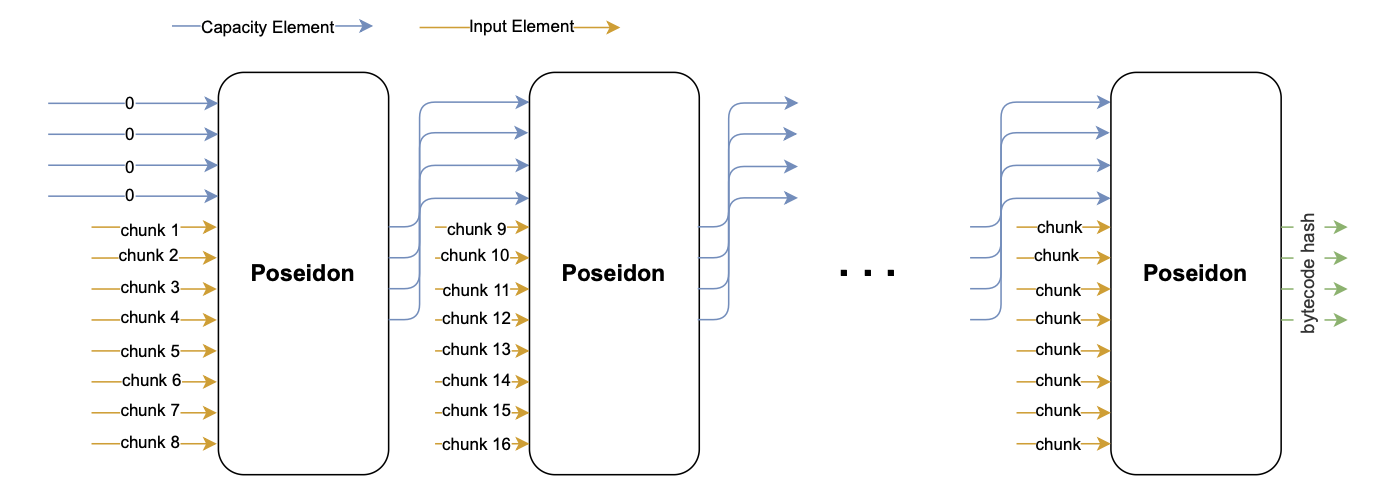
Smart contract bytecodes larger than 256 bits undergo a chained hashing process to obtain a valid representative value (called ).
More specifically, the padded bytecode is split into chunks of 7 bytes, and 8 of these chunks are recursively added as input values of the Poseidon hash function.
Although the initial capacity value is , all subsequent capacity values are to the previous output of the Poseidon hash function.
-
Example. (Recursively chained Poseidon)
To illustrate this, let's follow on with the previous 2-byte example, , which was padded to:
Since the 56-byte padded bytecode amounts to 8 chunks of 7 bytes, performing a single Poseidon hashing is sufficient.
By setting the capacity to an array , where each is a 7-byte zero, the total input to the Poseidon hash function is as below:

Finally, the of the bytecode is .
Conclusion
The above construction of SMTs is efficient and optimal in many ways.
For instance, the design approach to avoid hashing the full height of an empty branch, but rather store it as a zero-leaf where the value stored is an explicit zero value, achieves huge storage savings.
In practical terms, this means that the branch node at level 1 assumes a specific value:
This type of optimization is called partial tree construction, where leaf nodes are at various levels in the tree.
Last updated on
L2 state tree concept
This document explains how the zkEVM proving system manages changes in the L2 state tree. The main components of the zkEVM proving system are, the ROM, the prov
Processing L2 blocks
In this document we discuss the differences between the Dragonfruit upgrade, which comes with the executor fork-ID 5, and the associated with fork-ID 6. The key